행렬분해
[일반인을 위한] K-MOOC 인공지능을 위한 기초수학 입문 (Introductory Mathematics for Artificial Intelligence) 이상구 with 이재화, 함윤미, 박경은 II. 인
matrix.skku.ac.kr
4. 행렬 분해를 이용한 잠재요인 협업 필터링
< 목차 > 용어정의 행렬 분해의 이해 확률적 경사하강법(SGD)를 이용한 행렬 분해 확률적 경사하강법(SGD) 활용예제 행렬 분해를 이용한 개인화 영화 추천시스템 개발 1. 용어정의 피드백 후 작성예
big-dream-world.tistory.com
행렬분해 : sparse의 공간 낭비를 줄이기 위해서
대각요소, 특이값
특이값 분해 : 행렬을 분해하는 과정에서 잠재적인 요인들로 유사한 아이템을 찾을 수 있다.
ratings.csv
2.33MB
movies.csv
0.44MB
# 모듈 및 데이터 불러오기
import pandas as pd
import numpy as np
from sklearn.decomposition import TruncatedSVD
from sklearn.metrics.pairwise import cosine_similarity
rate = pd.read_csv('ratings.csv')
movie = pd.read_csv('movies.csv')
rate.drop(columns=['timestamp'],inplace=True)
movie.drop(columns=['genres'],inplace=True)
data = rate.merge(movie, on=['movieId'])
# 아이템 기반 협업 필터링 추천 시스템 만들기
rated_1 = data.pivot_table('rating', index=['userId'], columns=['title']).fillna(0).T
sim1 = cosine_similarity(rated_1,rated_1)
sim1_df = pd.DataFrame(data = sim1, index = rated_1.index, columns=rated_1.index)
# xXx (2002) 영화와 유사한 영화를 추천하기
sim1_df['xXx (2002)'].sort_values(ascending=False)[1:31]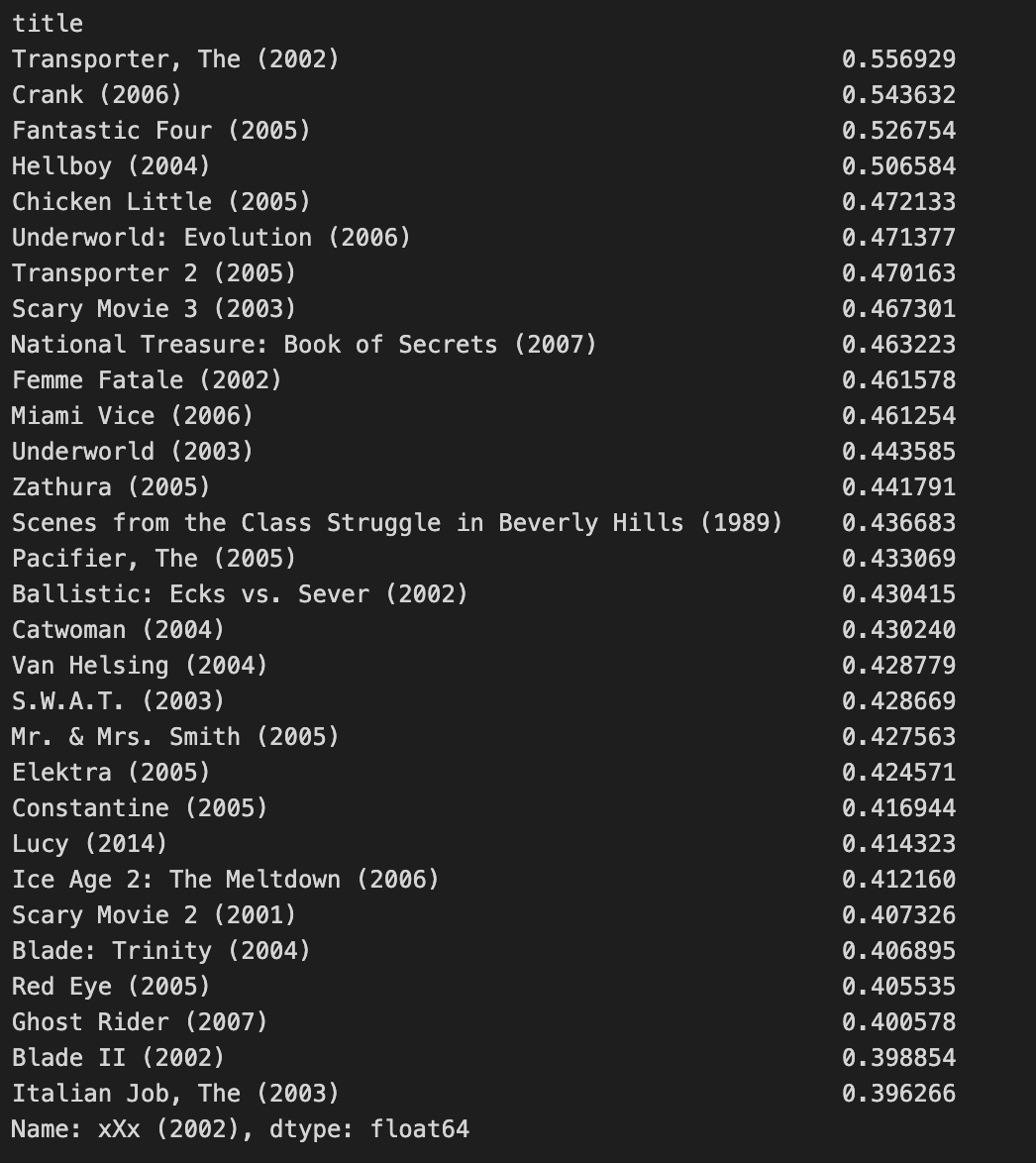
# 행렬 분해를 이용해서 추천 시스템 만들기
rated_val = rated_1.values
SVD = TruncatedSVD(n_components=15)
mat = SVD.fit_transform(rated_val)
movie_corr = np.corrcoef(mat)
movie_title = rated_1.index
movie_title_list = movie_title.tolist()
# 12 Years a Slave (2013) 영화와 유사한 영화를 추천하기
findMovie = movie_title_list.index('12 Years a Slave (2013)')
movie_title[movie_corr[findMovie]>=0.9].tolist()[1:]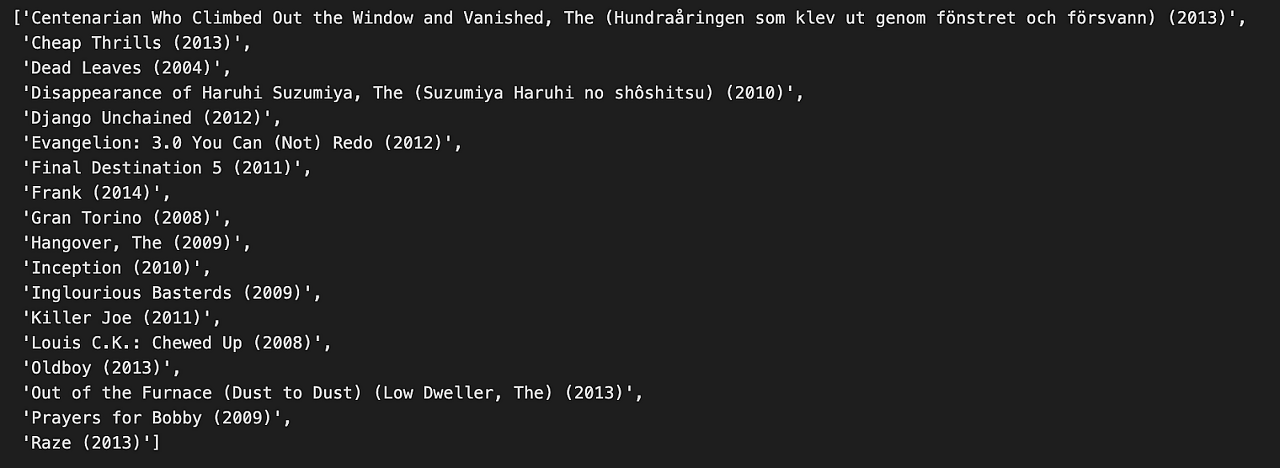
'ML & DL' 카테고리의 다른 글
| [딥러닝 이론] 다양한 CNN 모델 소개 (0) | 2023.05.10 |
|---|---|
| [딥러닝 이론] CNN 기본 모델 (0) | 2023.05.10 |
| [딥러닝이론] 합성곱 신경망이 패턴을 파악하는 방법 (0) | 2023.05.09 |
| [딥러닝이론] 인공신경망 (0) | 2023.05.03 |