타이타닉 생존자 예측을 위해 train 데이터로 우선 모델을 만들고자 한다.
데이터를 읽어와 df로 저장하고
import numpy as np
import pandas as pd
df=pd.read_csv('train.csv')
데이터의 기본 정보를 살펴보면 다음과 같다.

Age, Cabin, Embarked에 결측값이 있다.
Cabin의 결측값은 687개로 현재 데이터만으로는 결측값을 추정하여 채워넣기엔 무리가 있으므로 활용하지 않는다.
Age와 Embarked의 결측값을 추정해보기 위해 각 변수간의 상관관계를 분석해보았다.
상관관계 분석은 numpy의 corr을 사용하여 분석할 수 있는데 Sex, Embarked와 같은 명목형 변수는 숫자로 라벨링하여 가져와야 한다.
상관관계를 분석하기 위한 데이터프레임을 하나 초기화해주고
age_corr=pd.DataFrame()숫자로 입력되어있는 변수인 Survived, Pclass, Age, Sib Sp, Parch, Fare는 그냥 그대로 가져온다.
age_corr['Survived']=df['Survived']
age_corr['Pclass']=df['Pclass']
age_corr['Age']=df['Age']
age_corr['SibSp']=df['SibSp']
age_corr['Parch']=df['Parch']
age_corr['Family']=df['Family'] # Family = SibSp + Parch
age_corr['Fare']=df['Fare']Sex는 male과 female로 입력되어 있으므로 male은 0, female은 1로 변환하여 가져온다.
sex_dict={'female':1,'male':0}
age_corr['Sex']=df.Sex.map(lambda x: sex_dict[x])
Embarked는 2개의 결측값이 있는데, 관련 데이터 개수를 살펴본다.

Embarked는 승선지인데, 선실 등급인 Pclass가 승선지와 어느정도 관계가 있지 않을까 하여 그룹핑을 해보았다.

비율상으로는 1등급 선실 탑승객이 C지역이 가장 높았으나, 탑승객 수는 S지역이 제일 많았다.
승선지에 대한 정확한 정보가 없기도 하므로 가장 많은 인원이 탑승한 S지역으로 결측치를 채운다.
df['Embarked'].fillna('S',inplace=True)일단 여기까지의 데이터로 변수간 상관관계를 살펴본다.

Age와 눈에 띄게 상관관계가 높은 변수는 없지만 그나마 Pclass가 절댓값이 크게 나왔다. 따라서 Pclass별 Age 평균값으로 결측값을 대체한다.

그런데 이를 바로 채워넣으려고 하면 다음과 같은 오류가 뜬다.

연결된 링크로 들어가보니 원본 데이터를 직접적으로 많은 변경을 수행할 때 위와 같은 경고를 주고있다. 혹시 모를 실수를 대비해 복사본을 만들어 결측값을 채워주고 해당 인덱스를 찾아 데이터를 변경해주는 방식으로 처리했다.
p1=df.loc[df['Pclass']==1].copy()
p1['Age'].fillna(38.23, inplace=True)
for i in p1.index:
df.loc[i]=p1.loc[i]
p2=df.loc[df['Pclass']==2].copy()
p2['Age'].fillna(29.88, inplace=True)
for i in p2.index:
df.loc[i]=p2.loc[i]
p3=df.loc[df['Pclass']==3].copy()
p3['Age'].fillna(25.14, inplace=True)
for i in p3.index:
df.loc[i]=p3.loc[i]이렇게 결측값을 모두 채우면 전체 데이터 현황은 다음과 같다.

필요한 열의 결측값들이 전부 채워졌다!
아래는 결측값을 채운 후 변수간 상관계수이다.
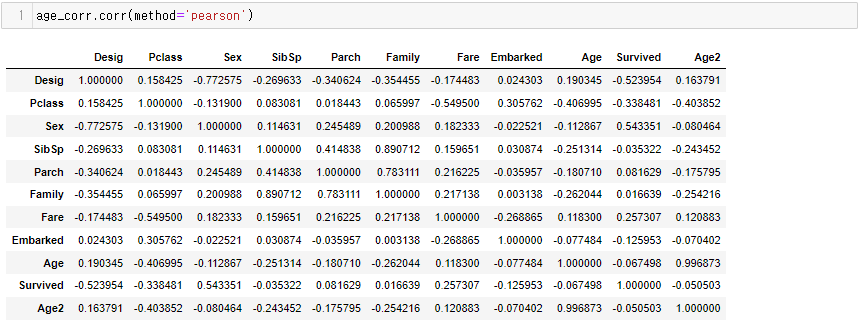
Age2가 위에서 수행한 Pclass별 평균으로 결측값을 채워넣었을 때의 결과이다.
Age는 Pclass별 Sex별 평균으로 결측값을 채워넣었을 때의 결과이다.

p1f=df.loc[(df['Pclass']==1) & (df['Sex']=='female')].copy()
p1f['Age'].fillna(34.61, inplace=True)
for i in p1f.index:
df.loc[i]=p1f.loc[i]
p1m=df.loc[(df['Pclass']==1) & (df['Sex']=='male')].copy()
p1m['Age'].fillna(41.28, inplace=True)
for i in p1m.index:
df.loc[i]=p1m.loc[i]
p2f=df.loc[(df['Pclass']==2) & (df['Sex']=='female')].copy()
p2f['Age'].fillna(28.72, inplace=True)
for i in p2f.index:
df.loc[i]=p2f.loc[i]
p2m=df.loc[(df['Pclass']==2) & (df['Sex']=='male')].copy()
p2m['Age'].fillna(30.74, inplace=True)
for i in p2m.index:
df.loc[i]=p2m.loc[i]
p3f=df.loc[(df['Pclass']==3) & (df['Sex']=='female')].copy()
p3f['Age'].fillna(21.75, inplace=True)
for i in p3f.index:
df.loc[i]=p3f.loc[i]
p3m=df.loc[(df['Pclass']==3) & (df['Sex']=='male')].copy()
p3m['Age'].fillna(26.51, inplace=True)
for i in p3m.index:
df.loc[i]=p3m.loc[i]
이 분석을 수행하는 궁극적인 목표는 Survived 여부를 예측하는 것이기 때문에 Survived와의 관계를 보지 않을 수 없다.
결측값을 채워넣기 전에는 Age와 Survived의 상관계수가 -0.077221이었으나, 결측값 대체 후에는 각각 -0.067498, -0.050503으로 수치가 떨어졌다. 애초에 -0.077221가 유의미한 수치는 아니긴 해도 이와 같은 수행을 통해 데이터의 조건을 세분화 했을 때 조금 더 정확한 예측에 도움이 될 수 있다는 점을 알 수 있었다.
아래는 원본 데이터를 다운받을 수 있는 페이지입니다.
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
'프로젝트' 카테고리의 다른 글
| [Kaggle] Chat GPT4가 추천하는 타이타닉 생존자 예측 참고자료 (0) | 2023.04.11 |
|---|